My research interest is in the intersection of Natural Language Processing and Computer Vision. Particularly, I am interested in multi-modal learning, language grounding and low-resource machine learning.
Multi-Modal Retrieval Augmentation for Open-Ended and Knowledge-Intensive Video Question Answering
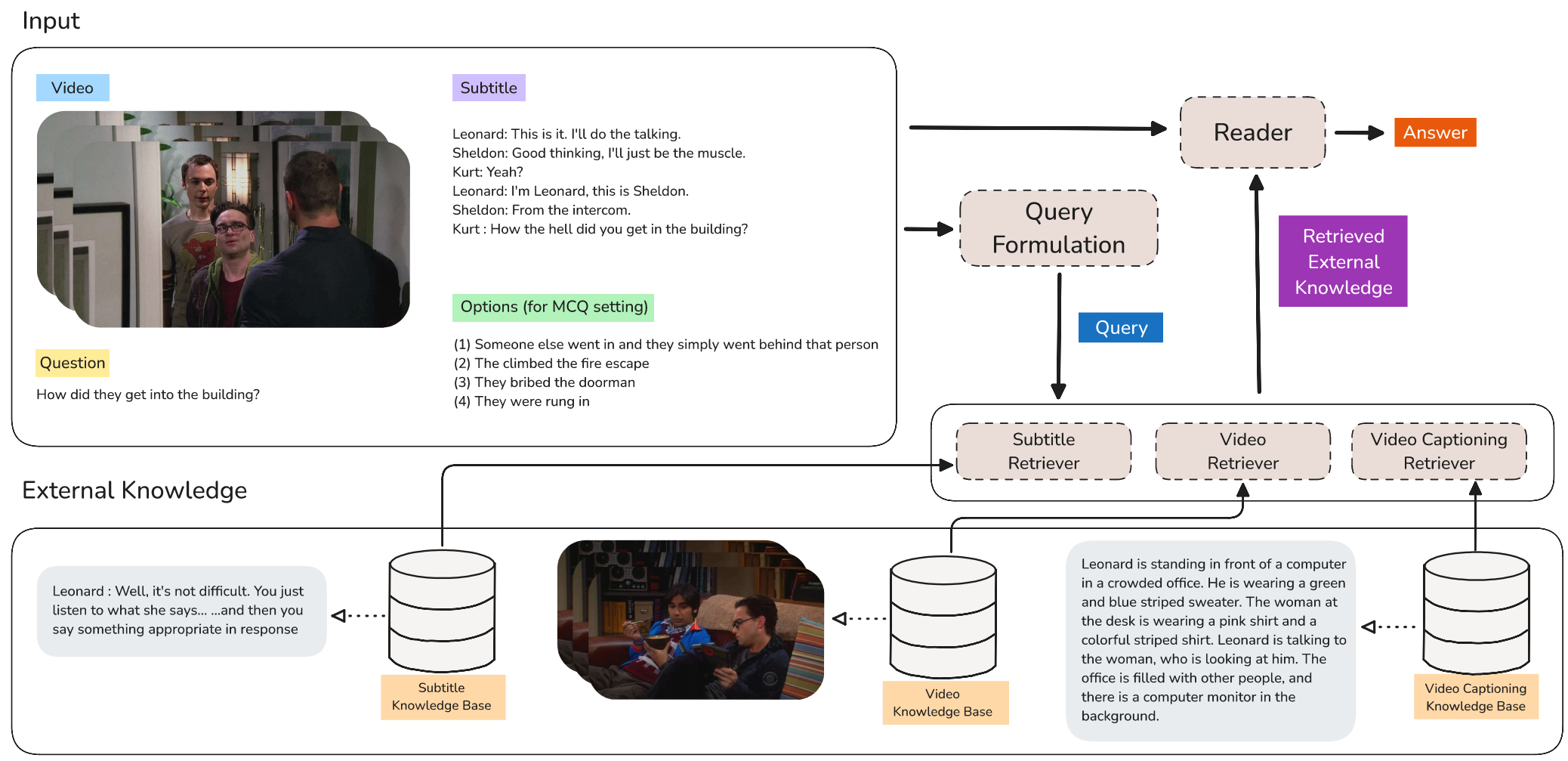
Working on improving Knowledge-Intensive Video Question Answering using Multi-Modal Retrieval Augmentation.
Collaborators
- Hamed Zamani — Associate Professor, CICS, UMass Amherst
Geospatial Language Model
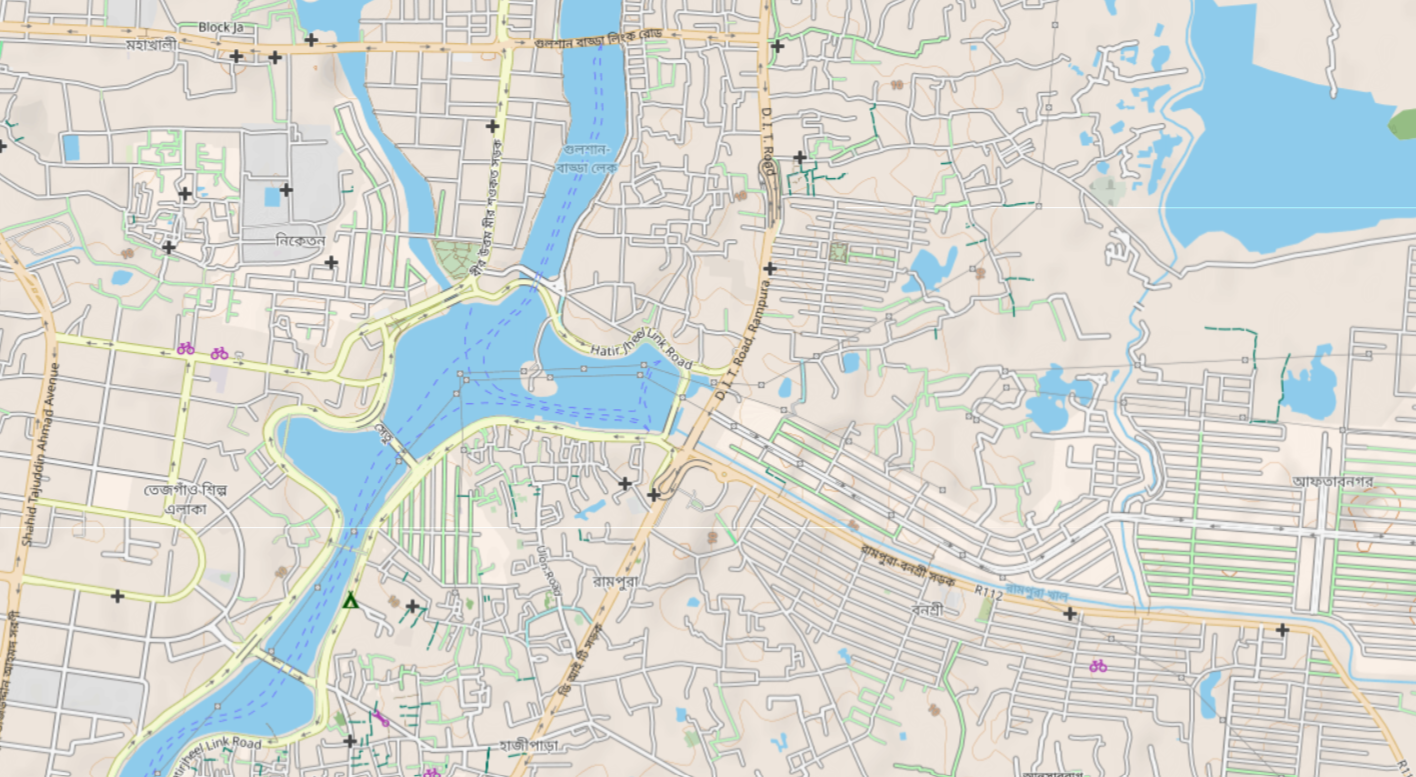
Worked on creating a geospatial language model that enhances the understanding of geo-entities in natural language, which in turn helps create an address matching platform specially tuned for house addresses — where platforms like Google Maps fail. This helps optimize delivery agents to deliver orders faster and more efficiently.
Collaborators
- Tejas Viswanath — CTO, Chaldal Ltd.
- Asif Imitial — SWE, Chaldal Ltd.
3D Particle Picking
Accepted at NeurIPS 2024 Workshop on Machine Learning in Structural Biology
Worked on developing a semi-supervised framework for 3D particle picking from macromolecular samples, which is able to detect particles directly from subtomograms.
Collaborators
- Ajmain Yasar Ahmed Sahil — BUET
Supervisors
- Mostofa Rafid Uddin — Graduate Research Assistant, CMU
- Dr. Min Xu — Associate Professor, CMU
Low-resource Computer Vision aided PD Recognition
Under review
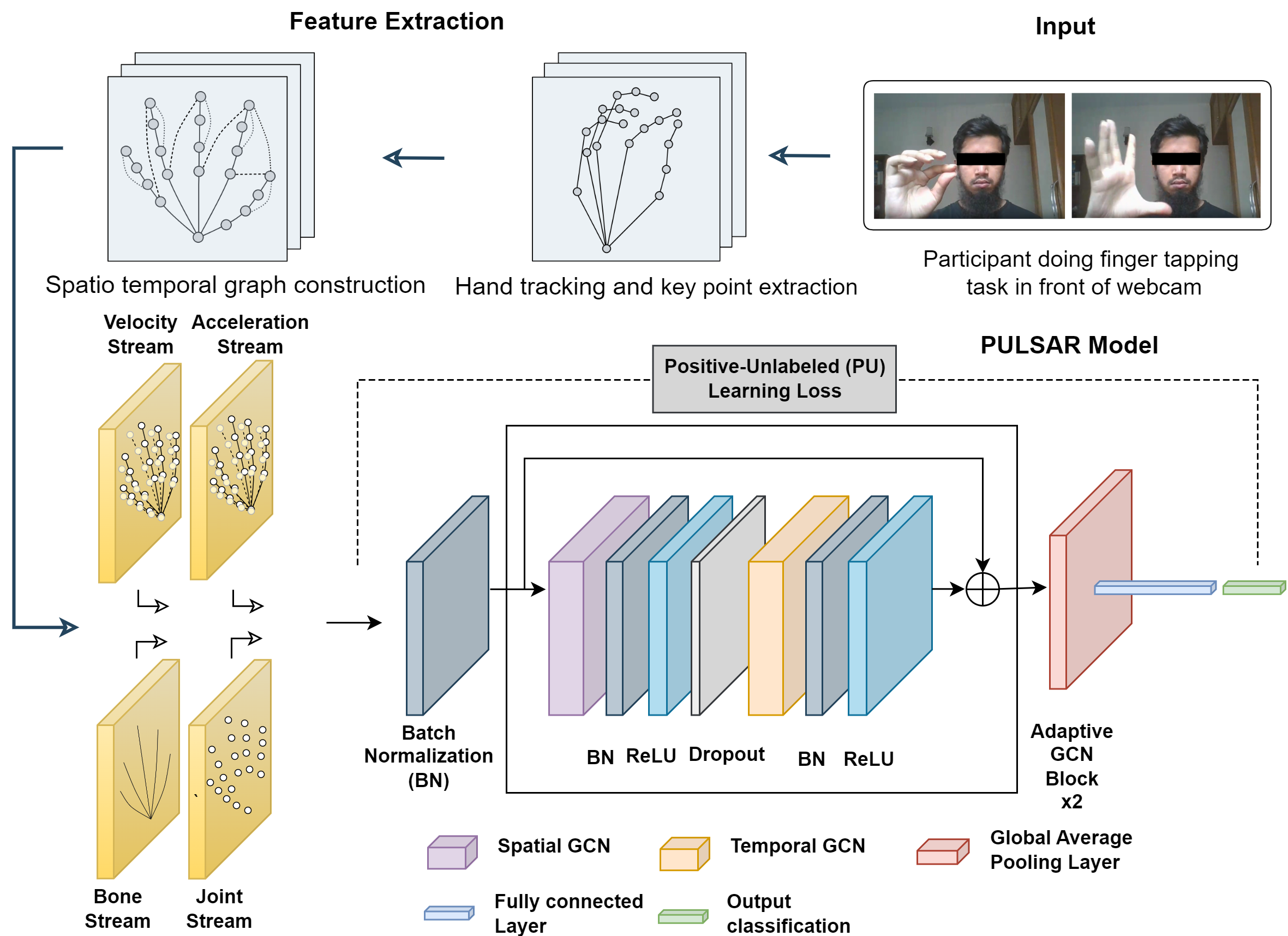
Developed `PULSAR`, an automated PD screening tool. It uses a spatio-temporal graph neural network to detect PD from videos. We were also the first to explore positive-unlabeled learning in this setting, addressing the lack of positive labels — generally the case in medical data. _**[Lead Investigator]**_
Collaborators
- Md. Saiful Islam — Graduate Research Assistant, University of Rochester
Supervisors
- Dr. Mohammad Saifur Rahman — Professor, BUET
- Dr. Ehsan Hoque — Associate Professor, University of Rochester
Quartet Fiduccia-Mattheyses Revisited for Larger Phylogenetic Studies
Accepted at Bioinformatics (Oxford University Press) Journal
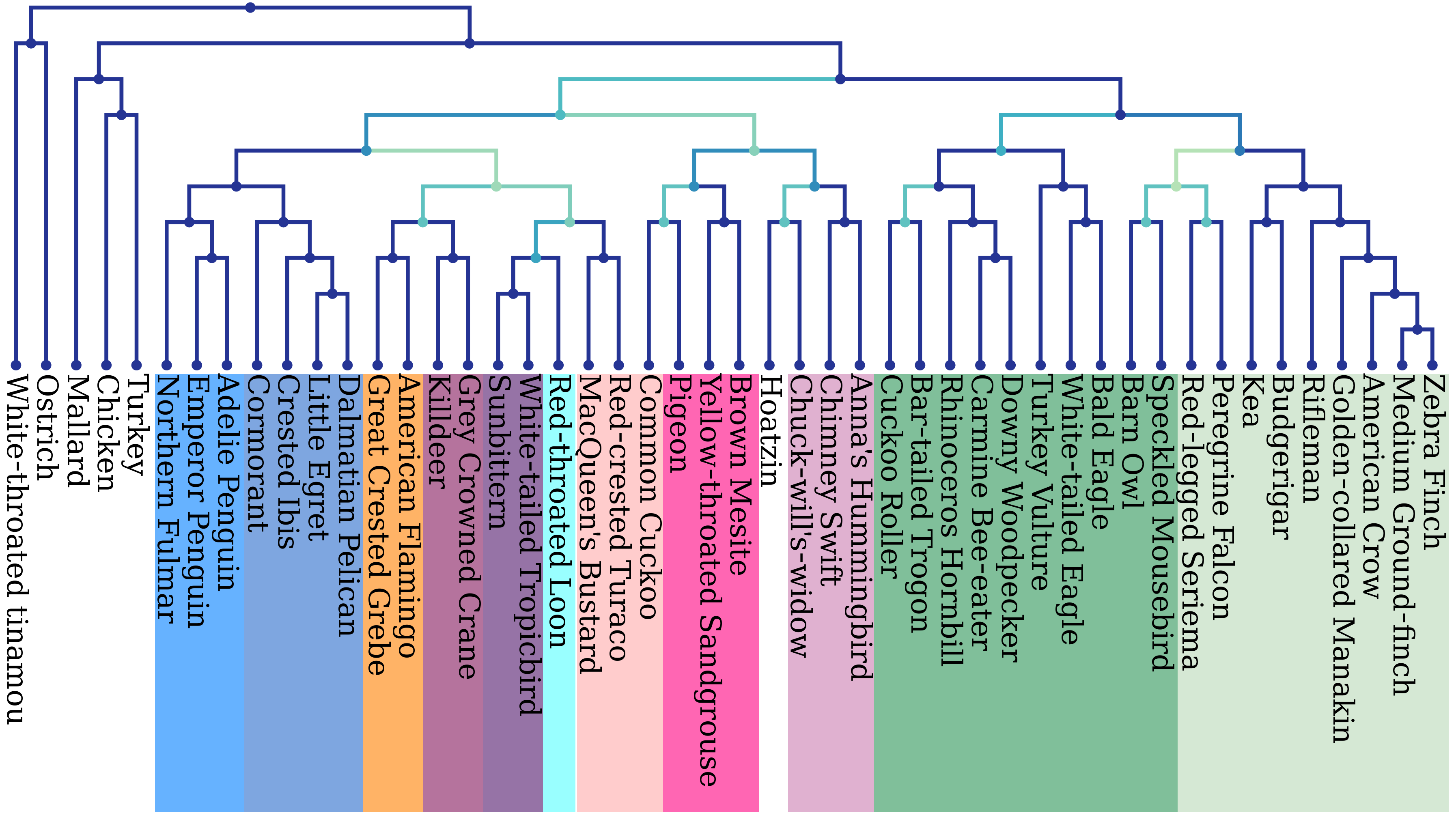
Our proposed method QFM-FI, a faster and improved version of the QFM algorithm, can amalgamate millions of quartets over thousands of taxa into a species tree with a great level of accuracy. This also achieves a speedup of 20,000× compared to its predecessor. Worked on providing a theoretical analysis of the running time and memory requirements of QFM-FI.
Collaborators
- Sharmin Akter Mim — BUET
Supervisors
- Dr. Mohammad Saifur Rahman — Professor, BUET
- Dr. Md Shamsuzzoha Bayzid — Associate Professor, BUET
- Dr. Rezwana Reaz — Assistant Professor, BUET
Other Research & Independent Exploration
Personalized Recommendation System
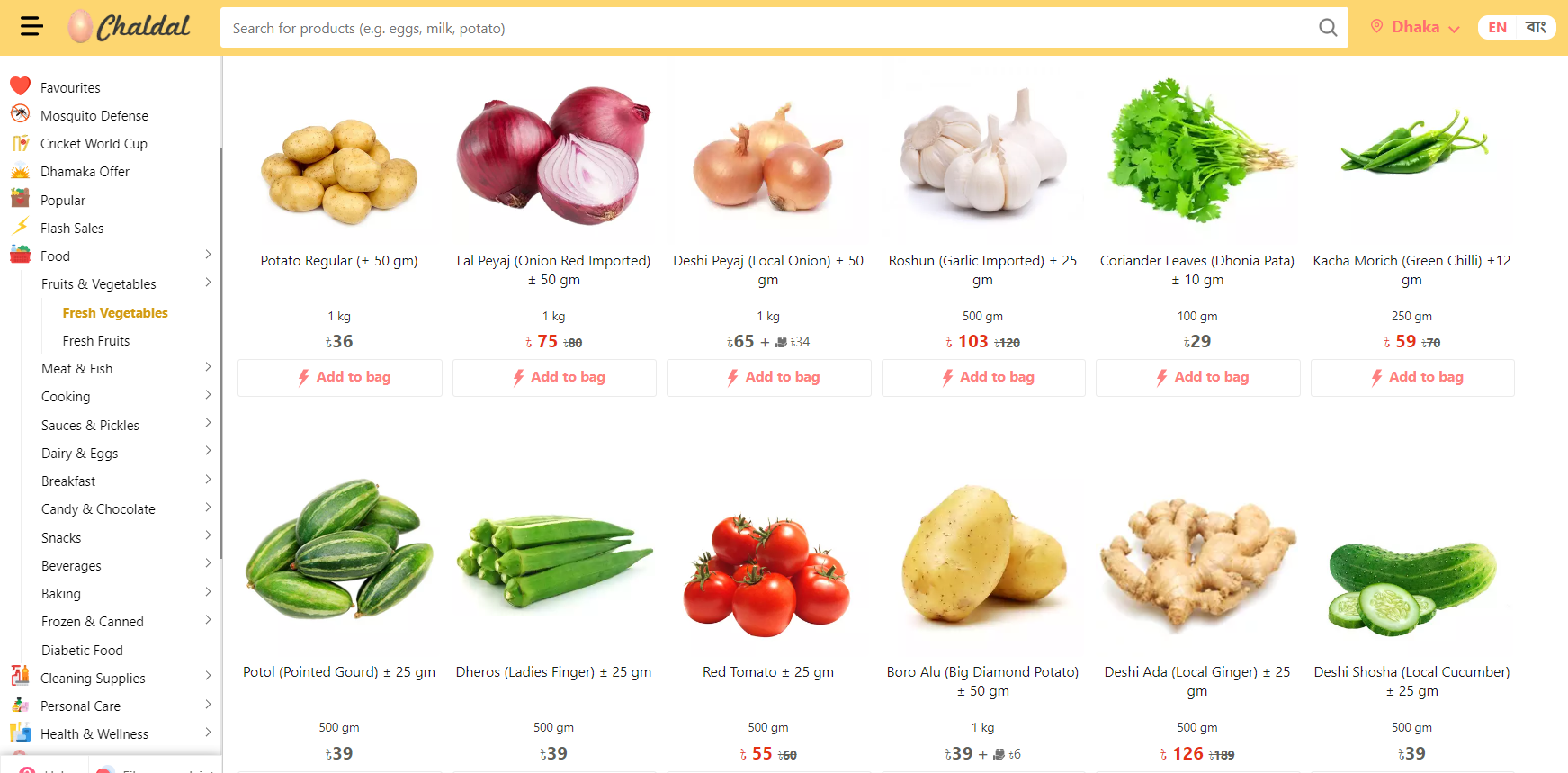
Developing an in-house personalized recommender system from the ground up for the leading online platform ([Chaldal.com](https://chaldal.com/)) for grocery and delivery in Bangladesh, scaling it to serve more than one million users.
Collaborators
- Anand Bhaskar — Research Scientist, Meta
- Rohit Vaz — VP of Engineering, Chaldal Ltd.
- Asif Imitial — SWE, Chaldal Ltd.
Bangla Plagiarism Detection
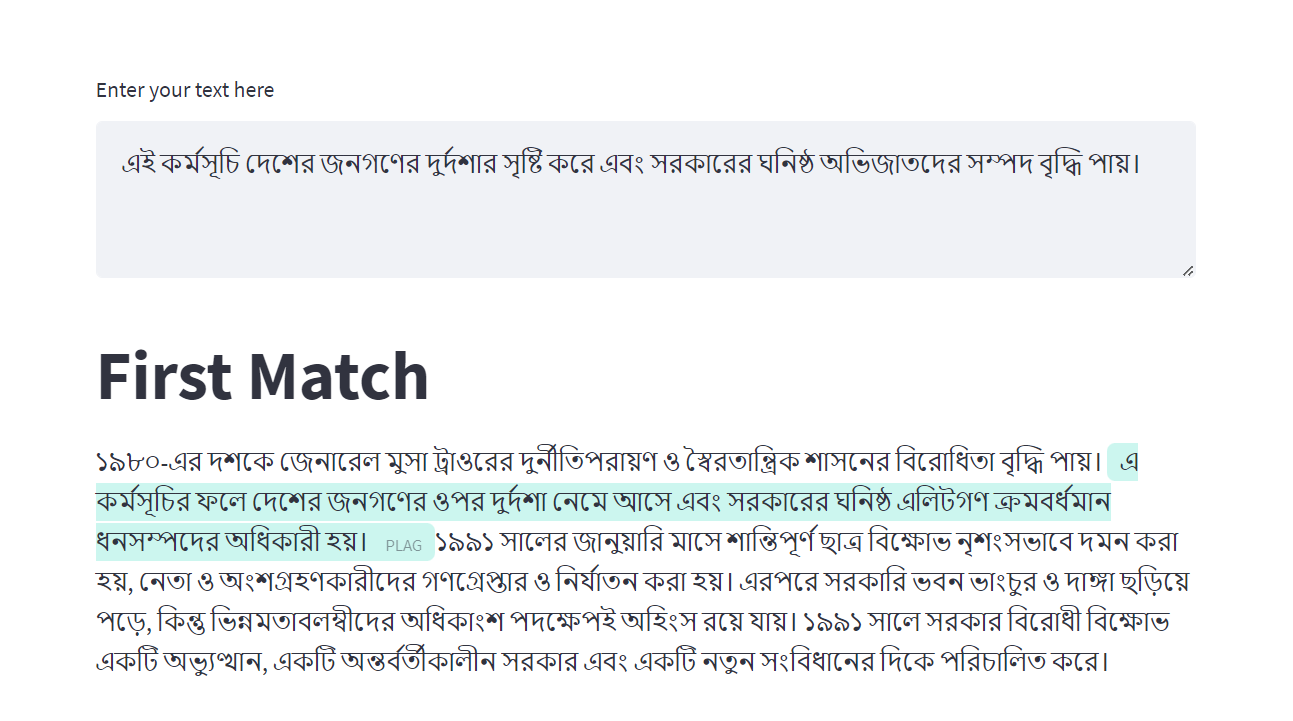
We created the first Bangla Plagiarism Dataset (available on [Hugging Face 🤗](https://huggingface.co/datasets/zarif98sjs/bangla-plagiarism-dataset)) using a semi-supervised approach as part of our Machine Learning project. We also proposed two distinct approaches for detecting plagiarism: the first fine-tunes Bangla BERT, while the second uses sentence embeddings for multi-document plagiarism detection.
Collaborators
- Ramisa Alam — BUET
Supervisors
- Md. Tareq Mahmood — Assistant Professor, BUET
Occam's Razor Strikes Again: Revisiting Short-Text Stream Clustering with Latest Sentence Embeddings
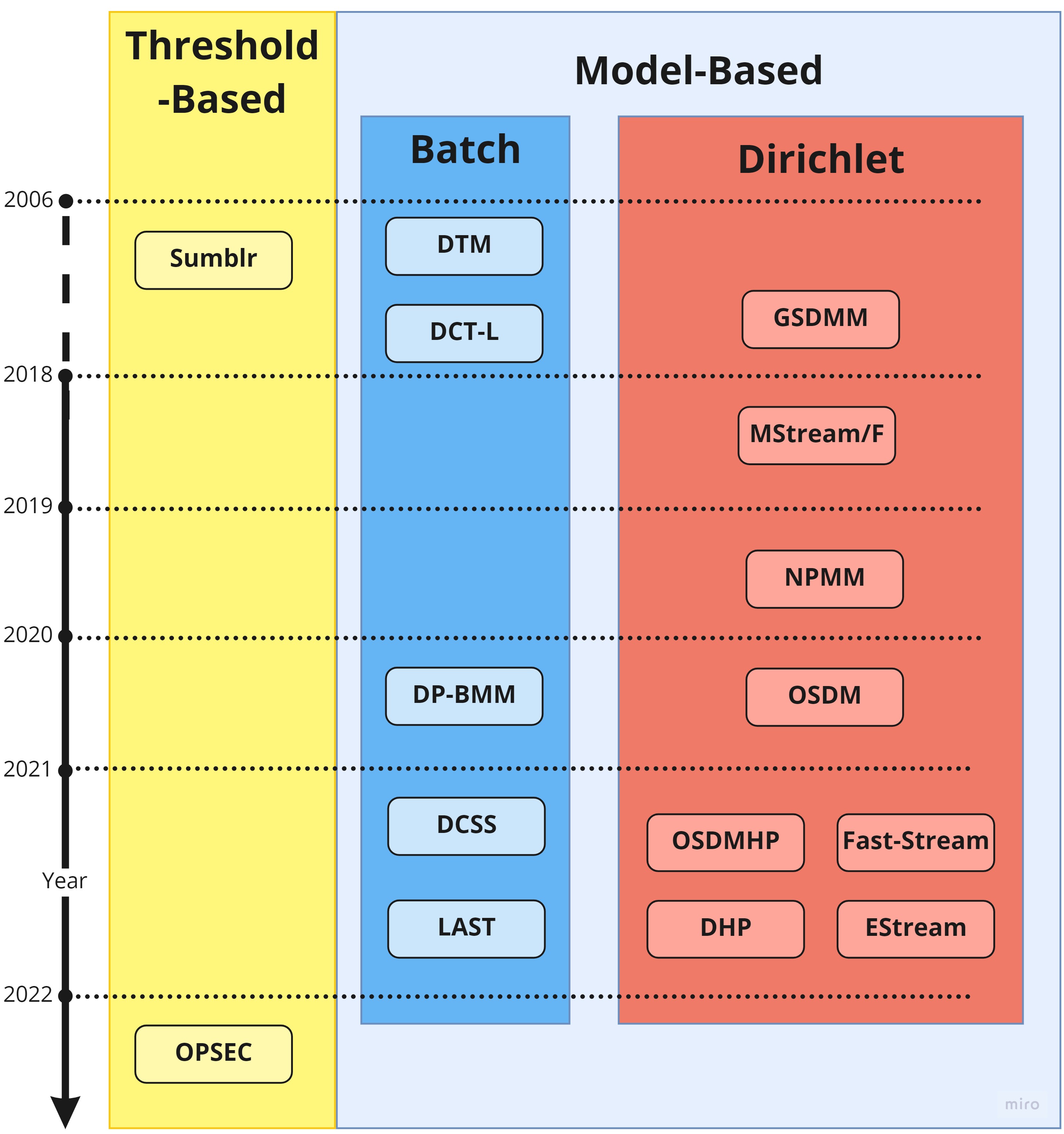
During the height of COVID-19, online classes were the new normal. The rise of MOOCs led to an interesting research question — given a large number of questions already posed by students, how can we detect repetitive questions in real time and unify them as a single question for the instructor? Under the supervision of Prof. Subhra Kanti Karmaker, I worked on this problem of online short-text clustering. We developed One Pass Sentence Embedding Clustering (OPSEC), which efficiently clusters short text streams using a unique one-pass algorithm based on sentence embeddings. It was used as an internal tool to cluster questions in online classes at Auburn.
Collaborators
- Minh Smith — Auburn University
- Ramisa Alam — BUET
Supervisors
- Dr. Shubhra Kanti Karmaker — Assistant Professor, Auburn University
- Dr. Anindya Iqbal — Professor, BUET
Bangla Sign Language Recognition

**Sign language**, as a different form of communication, is important to large groups of people in society. Each sign is unique due to variations in hand form, motion profile, and positioning of the hand, face, and other body components, making visual sign language recognition a complex computer vision problem. In this work, we present a new **word-level Bangla Sign Language (BdSL)** [dataset](https://github.com/Patchwork53/BdSL40_Dataset_AI_for_Bangla_2.0_Honorable_Mention) of 611 videos over 40 BdSL words, along with two approaches: a 3D Convolutional Neural Network and a novel Graph Neural Network. To the best of our knowledge, this is the **first study on word-level BdSL recognition**. The proposed GNN model achieved an F1 score of 89%.
Supervised 4 junior-year undergraduates in this project!
Collaborators
- H.A.Z. Sameen Shahgir — BUET
- Khondker Salman Sayeed — BUET
- Md Toki Tahmid — BUET
- Tanjeem Azwad Zaman — BUET